DNA Defined
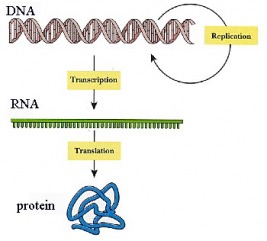
During the 1950s, a tremendous explosion of biological research occurred, and the methods of gene expression were elucidated. The knowledge generated during this period helped explain how genes function, and it gave rise to the science of molecular genetics. This science is based on the activity of deoxyribonucleic acid (DNA) and how this activity brings about the production of proteins in the cell. Genetic material is packaged into DNA molecules. DNA molecules relay the inherited information to messenger RNA (mRNA) which, in turn, codes for proteins. This chain of command is represented as: DNA --> mRNA --> Protein
The flow of information from DNA to protein is known as the Central Dogma of molecular biology. In 1953, two biochemists, James D. Watson and Francis H.C. Crick, proposed a model for the structure of DNA. (In 1962, they shared a Nobel Prize for their work.) The publication of the structure of DNA opened a new realm of molecular genetics. Its structure provided valuable insight into how genes operate and how DNA can reproduce itself during mitosis, thereby passing on hereditary characteristics. Not only did the new research uncover many of the principles of protein synthesis, but it also gave rise to the science of biotechnology and genetic engineering.
DNA Structure
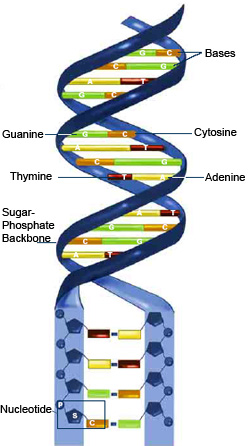
As proposed by Watson and Crick, deoxyribonucleic acid (DNA) consists of two long nucleotide chains. The two nucleotide chains twist around one another to form a double helix, a shape resembling a spiral staircase. Weak chemical bonds between the chains hold the two chains of nucleotides to one another.
A nucleotide in the DNA chain consists of three parts: a nitrogenous base, a phosphate group, and a molecule of deoxyribose. The nitrogenous bases of each nucleotide chain are of two major types: purines and pyrimidines. Purine bases have two fused rings of carbon and nitrogen atoms, while pyrimidines have only one ring. The two purine bases in DNA are adenine (A) and guanine (G). The pyrimidine bases in DNA are cytosine (C) and thymine (T). Purines and pyrimidine bases are found in both strands of the double helix.
The phosphate group of DNA is derived from a molecule of phosphoric acid. The phosphate group connects the deoxyribose molecules to one another in the nucleotide chain. Deoxyribose is a five-carbon carbohydrate. The purine and pyrimidine bases are attached to the deoxyribose molecules, and the purine and pyrimidine bases are opposite one another on the two nucleotide chains. Adenine is always opposite thymine and binds to thymine. Guanine is always opposite cytosine and binds to cytosine. Adenine and thymine are said to be complementary, as are guanine and cytosine This is known as the principle of complementary base pairing.
DNA Replication
Before a cell enters the process of mitosis, its DNA replicates itself. Equal copies of the DNA pass into the daughter cells at the end of mitosis. In human cells, this means that 46 chromosomes (or molecules of DNA) replicate to form 92 chromosomes. (For more detailed notes, download the Word Document File at the bottom of the page called "DNA Replication")
The process of DNA replication begins when specialized enzymes pull apart, or "unzip," the DNA double helix (see Figure 1 ). As the two strands separate, the purine and pyrimidine bases on each strand are exposed. The exposed bases then attract their complementary bases. Deoxyribose molecules and phosphate groups are present in the nucleus. The enzyme DNA polymerase joins all the nucleotide components to one another, forming a long strand of nucleotides. Thus, the old strand of DNA directs the synthesis of a new strand of DNA through complementary base pairing. The old strand then unites with the new strand to reform a double helix. This process is called semiconservative replication because one of the old strands is conserved in the new DNA double helix.
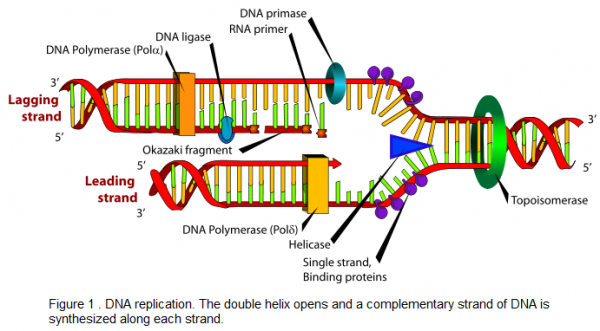
DNA polymerase joins nucleotides in a 5′-3′ direction on the leading strand, shown in Figure 1 . However, DNA polymerase does not elongate a DNA strand in a 3′-5′ direction. Therefore, the 3′-5′ strand, called the lagging strand, is synthesized in short segments in a 5′-3′ direction. These short segments placed on the lagging strand are Okazaki fragments and are ultimately joined together by the enzyme DNA ligase to form a new DNA strand.
DNA replication occurs during the S phase of the cell cycle. After replication has taken place, the chromosomal material shortens and thickens. The chromatids appear in the prophase of the next mitosis. The process then continues, and eventually two daughter cells form, each with the identical amount and kind of DNA as the parent cell. The process of DNA replication thus ensures that the molecular material passes to the offspring cells in equal amounts and types.
Protein Synthesis
During the 1950s and 1960s, it became apparent that DNA is essential in the synthesis of proteins. Proteins are used in enzymes and as structural materials in cells. Many specialized proteins function in cellular activities. For example, in humans, the hormone insulin and the muscle cell filaments are composed of protein. The hair, skin, and nails of humans are composed of proteins, as are all the hundreds of thousands of enzymes in the body. (For more detailed notes, download the Microsoft Word File at the bottom of the page called, "Transcription and Translation")
The key to a protein molecule is how the amino acids are linked. The sequence of amino acids in a protein is a type of code that specifies the protein and distinguishes one protein from another. A genetic code in the DNA determines this amino acid code. The genetic code consists of the sequence of nitrogenous bases in the DNA. How the nitrogenous base code is translated to an amino acid sequence in a protein is the basis for protein synthesis.
For protein synthesis to occur, several essential materials must be present, such as a supply of the 20 amino acids, which comprise most proteins. Another essential element is a series of enzymes that will function in the process. DNA and another form of nucleic acid called ribonucleic acid (RNA) are essential.
RNA is the nucleic acid that carries instructions from the nuclear DNA into the cytoplasm, where protein is synthesized. RNA is similar to DNA, with two exceptions. First, the carbohydrate in RNA is ribose rather than deoxyribose, and second, RNA nucleotides contain the pyrimidine uracil rather than thymine.
Types of RNA
In the synthesis of protein, three types of RNA function. The first type is called ribosomal RNA (rRNA). This form of RNA is used to manufacture ribosomes. Ribosomes are ultramicroscopic particles of rRNA and protein. They are the places (the chemical "workbenches") where amino acids are linked to one another to synthesize proteins. Ribosomes may exist along the membranes of the endoplasmic reticulum or in the cytoplasm of the cell.
A second important type of RNA is transfer RNA (tRNA). Transfer RNA exists in the cell cytoplasm and carries amino acids to the ribosomes for protein synthesis. When protein synthesis is taking place, enzymes link tRNA molecules to amino acids in a highly specific manner. For example, tRNA molecule X will link only to amino acid X; tRNA Y will link only to amino acid Y.
The third form of RNA is messenger RNA (mRNA). In the nucleus, messenger RNA receives the genetic code in the DNA and carries the code into the cytoplasm where protein synthesis takes place. Messenger RNA is synthesized in the nucleus at the DNA molecules. During the synthesis, the genetic information is transferred from the DNA molecule to the mRNA molecule. In this way, a genetic code can be used to synthesize a protein in a distant location. RNA polymerase, an enzyme, accomplishes mRNA, tRNA, and rRNA synthesis.
Transcription
Transcription is one of the first processes in the mechanism of protein synthesis. In transcription, a complementary strand of mRNA is synthesized according to the nitrogenous base code of DNA. To begin, the enzyme RNA polymerase binds to an area of one of the DNA molecules in the double helix. (During transcription, only one DNA strand serves as a template for RNA synthesis. The other DNA strand remains dormant.) The enzyme moves along the DNA strand and "reads" the nucleotides one by one. Similar to the process of DNA replication, the new nucleic acid strand elongates in a 5′-3′ direction, as shown in Figure 1 . The enzyme selects complementary bases from available nucleotides and positions them in an mRNA molecule according to the principle of complementary base pairing. The chain of mRNA lengthens until a "stop" message is received.
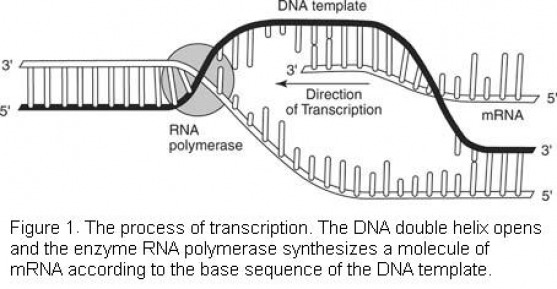
The nucleotides of the DNA strands are read in groups of three. Each group is a codon. Thus, a codon may be CGA, or TTA, or GCT, or any other combination of the four bases, depending on their sequence in the DNA strand. Each codon will later serve as a "code word" for an amino acid. First, however, the codons are transcribed to the mRNA molecule. Thus, the mRNA molecule consists of nothing more than a series of codons received from the genetic message in the DNA.
After the "stop" codon is reached, the synthesis of the mRNA comes to an end. The mRNA molecule leaves the DNA molecule, and the DNA molecule rewinds to form a double helix. Meanwhile, the mRNA molecule passes through a pore in the nucleus and proceeds into the cellular cytoplasm where it moves toward the ribosomes.
Translation
The genetic code is transferred to an amino acid sequence in a protein through the translation process, which begins with the arrival of the mRNA molecule at the ribosome. While the mRNA was being synthesized, tRNA molecules were uniting with their specific amino acids according to the activity of specific enzymes. The tRNA molecules then began transporting their amino acids to the ribosomes to meet the mRNA molecule.
After it arrives at the ribosomes, the mRNA molecule exposes its bases in sets of three, the codons. Each codon has a complementary codon called an anticodon on a tRNA molecule. When the codon of the mRNA molecule complements the anticodon on the tRNA molecule, the latter places the particular amino acid in that position. Then the next codon of the mRNA is exposed, and the complementary anticodon of a tRNA molecule matches with it. The amino acid carried by the second tRNA molecule is positioned next to the first amino acid, and the two are linked. At this point, the tRNA molecules release their amino acids and return to the cytoplasm to link up with new molecules of amino acid.
When it's time for the next amino acid to be positioned in the growing protein, a new codon on the mRNA molecule is exposed, and the complementary three-base anticodon of a tRNA molecule positions itself opposite the codon. This brings another amino acid into position, and that amino acid links to the previous amino acids. The ribosome moves further down the mRNA molecule and exposes another codon, which attracts another tRNA molecule with its anticodon.
One by one, amino acids are added to the growing chain until the ribosome has moved down to the end of the mRNA molecule. Because of the specificity of tRNA molecules for their individual amino acids, and because of the base pairing between codons and anticodons, the sequence of codons on the mRNA molecule determines the sequence of amino acids in the protein being constructed. And because the codon sequence of the mRNA complements the codon sequence of the DNA, the DNA molecule ultimately directs the amino acid sequencing in proteins. The primary "start" codon on an mRNA molecule is AUG, which codes for the amino acid methionine. Therefore, each mRNA transcript begins with the AUG codon, and the resulting peptide begins with methionine.
Figure 2 shows that the process of protein synthesis begins with the production of mRNA (upper right). The mRNA molecule proceeds to the ribosome where it meets tRNA molecules carrying amino acids (upper left). The tRNA molecule has a base code that complements the mRNA code and thereby brings a specific amino acid into position. The amino acids join together in peptide bonds (bottom), and the tRNA molecules are released to pick up additional amino acid molecules.
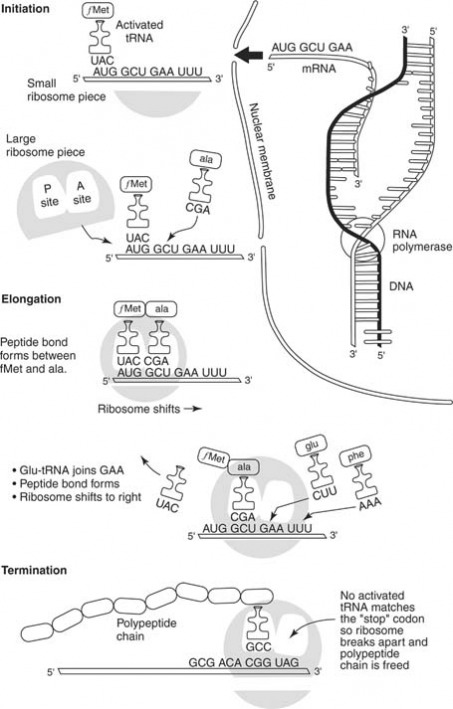
After the protein has been synthesized completely, it is removed from the ribosome for further processing and to perform its function. For example, the protein may be stored in the Golgi body before being released by the cell, or it may be stored in the lysosome as a digestive enzyme. Also, a protein may be used in the cell as a structural component, or it may be released as a hormone, such as insulin. After synthesis, the mRNA molecule breaks up and the nucleotides return to the nucleus. The tRNA molecules return to the cytoplasm to unite with fresh molecules of amino acids, and the ribosome awaits the arrival of a new mRNA molecule.
Gene control
The process of protein synthesis does not occur constantly in the cell. Rather, it occurs at intervals followed by periods of genetic "silence." Thus the cell regulates and controls the gene expression process.
The control of gene expression may occur at several levels in the cell. For example, genes rarely operate during mitosis, when the DNA fibers shorten and thicken to form chromatids. The inactive chromatin is compacted and tightly coiled, and this coiling regulates access to the genes.
Other levels of gene control can occur during and after transcription. In transcription, certain segments of DNA can increase and accelerate the activity of nearby genes. After transcription has taken place, the mRNA molecule can be altered to regulate gene activity. For example, researchers have found that an mRNA molecule contains many useless bits of RNA that are removed in the production of the final mRNA molecule. These useless bits of nucleic acid are called introns. The remaining pieces of mRNA, called exons, are then spliced to form the final mRNA molecule. Thus, through removal of introns and the retention of exons, the cell can alter the message received from the DNA and control gene expression.
The concept of gene control has been researched thoroughly in bacteria. In these microorganisms, genes have been identified as structural genes, regulator genes, and control genes (or control regions). The three units form a functional unit called the operon.
The operon has been examined in close detail in certain bacteria. Scientists have found, for example, that certain carbohydrates can induce the presence of the enzymes needed to digest those carbohydrates. When lactose is present, bacteria synthesize the enzyme needed to break down the lactose. Lactose acts as the inducer molecule in the following way: In the absence of lactose, a regulator gene produces a repressor, and the repressor binds to a control region called the operator. This binding prevents the structural genes from encoding the enzyme for lactose digestion. When lactose is present, however, it binds to the repressor and thereby removes the repressor at the operator site. With the operator site free, the structural genes are free to produce their lactose-digesting enzyme.
The operon system in bacteria shows how gene expression can occur in relatively simple cells. The gene is inactive until it is needed and is active when it becomes necessary to produce an enzyme. Other methods of gene control are more complex and are currently being researched.
Download DNA Replication onto Microsoft Word!
| dna_replication.doc | |
| File Size: | 202 kb |
| File Type: | doc |
Download Transcription and Translation onto Microsoft Word!
| transcription_and_translation.doc | |
| File Size: | 652 kb |
| File Type: | doc |
